2025年はAIの進化が、エンジニアのキャリアや企業の採用活動に大きな影響を与えています。この変化の最前線で、LAPRASのR&DチームはどのようにAIを価値ある機能へと昇華させているのでしょうか。
本記事では、5つのAI機能開発の具体的なエピソードを通して、HR領域におけるAI活用の現在地と、LAPRASが目指す「最適なマッチング」の未来像を明らかにしていきます。「当たり前」の品質を超え、いかに「ユーザーの心を動かすか」を問い続ける開発の裏側に迫ります。
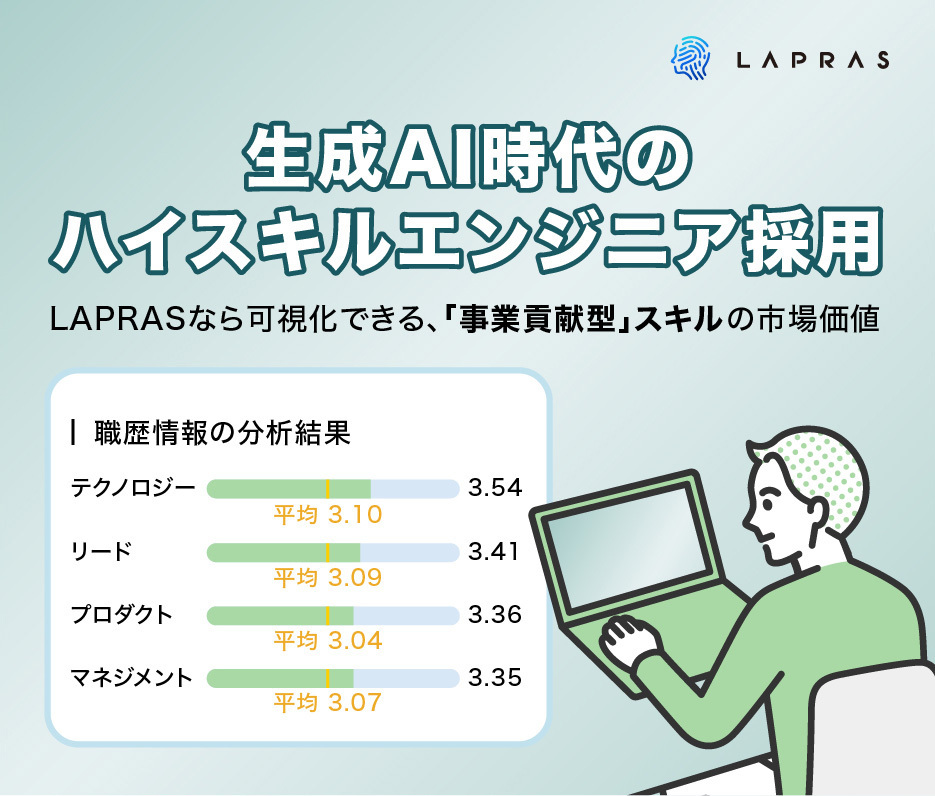
AI時代に高まる開発以外のスキルの重要性
「コードを書く」ことから「事業貢献」へ。マネジメント・リードなど、「作る以外の役割」を果たせるエンジニアのニーズが、ますます高まりを見せています。
事業成長を牽引するこれらのスキル、LAPRASなら見極められます!
「AI時代に求められるエンジニア」を見つける方法目次
<インタビュイー紹介>
Junpei Tajima(田嶋):フルスタックエンジニア

フロントエンドからバックエンドまでこなすフルスタックエンジニア。ゲームや金融などさまざまな業界を経験した後、2020年9月にLAPRASに入社。日本語の研究が趣味。
Ayaka Morimoto(森元):機械学習エンジニア・リサーチャー

最先端情報工学専攻にて修士号を取得。情報科学研究科の博士後期課程を指導認定退学。自然言語処理学の研究に従事し国際学会にて成果を発表。2019年4月より新卒でLAPRASに入社。趣味はアニメ鑑賞と1人でできる系のゲーム。
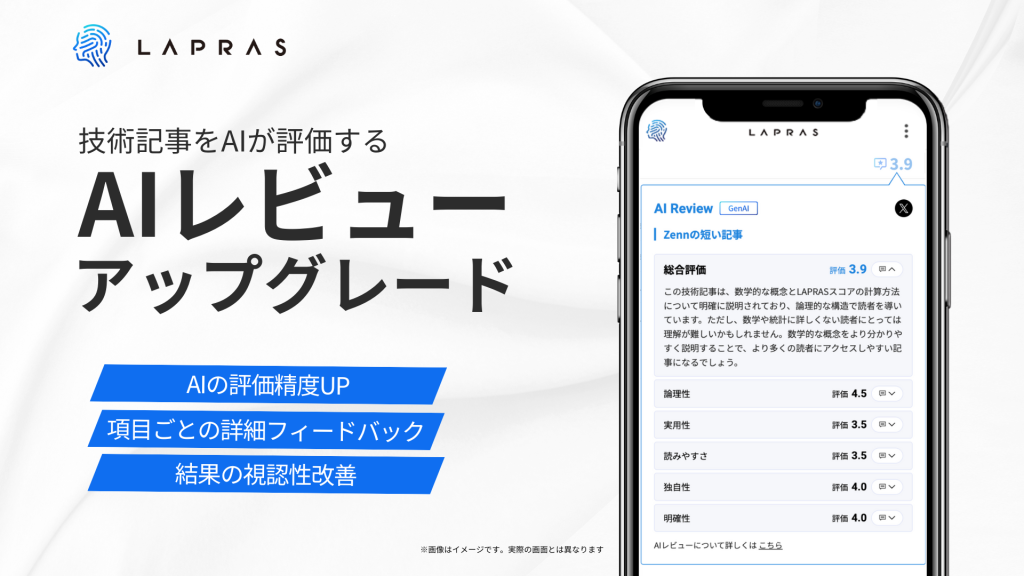
利用者のインサイトを追求した「AIレビュー」機能の裏側
――本日は、2025年に入ってからR&Dチームが中心となって開発・改善に携わった5つの機能についてお尋ねします。
田嶋さん:よろしくお願いします。
――まずは「AIレビュー」機能について、開発する上で特に気を付けた点はありましたか?
<AIレビュー機能とは?>
- ユーザーがQiitaやZennなどで公開した技術記事のURLを入力するだけで、AIが「論理性」や「実用性」など5つの観点で内容を評価・レビューする機能です。
- 今回のアップデートでは、そのAIモデルを最新化し、従来よりも詳細なフィードバックを得られるようになりました。
▼詳しくはこちら
https://corp.lapras.com/news/1097/
田嶋さん:はい、「AIレビュー」機能自体は2年以上前にリリースされていましたが、今回はその中核となる「AIモデルをバージョンアップする」というプロジェクトでした。
最も気を付けたのは、以前のバージョン(ver.1)から性能がデグレード(低下)しないようにすることでした。
――デグレードを防ぐために、具体的にどんな取り組みをしましたか?
田嶋さん:ver.1を開発した際に、「評価セット」というものを作成していました。これは、「論理性」「読みやすさ」といった複数の軸で様々な技術記事を人間が5段階評価したものです。
そして、当時のAIモデルが算出するスコアと、人間が付けた評価との間に一定の相関があることを確認していました。
今回のバージョンアップでも、この評価セットを活用し、新しいモデルによる出力と人間による評価の相関係数が、ver.1の時よりも低下していないかを厳しくチェックしました。
――なるほど、人間による評価との相関を見ることで、AIによる評価の信頼性を担保したのですね。
田嶋さん:はい。それに加えて、今回は定性的な評価も重視しました。というのも、モデルを新しくするにあたって、利用できるLLMの選択肢が複数あったためです。
森元さん:モデルごとに出力されるレビューの傾向が少しずつ違っていて。「淡々とした事実を伝える方が良いのか」「もっと書き手に寄り添うような丁寧な表現が良いのか」など、どのモデルがユーザーに最も喜ばれるのか、私たちだけでは判断がつきませんでした。
田嶋さん:そこで、よりユーザーの目線に近い社内のエンジニア十数名に協力してもらい、アンケートを実施しました。どのモデルが出力したレビューか分からないように情報を隠した状態で、「どのレビューが一番良いか」を純粋に評価してもらったんです。
――ブラインドテストをされたのですね。結果はいかがでしたか?
田嶋さん:これが非常に興味深い結果で。LAPRASのエンジニアは、少し厳しめというか、「辛口」なレビューを好む傾向があることが分かりました。結果的に、最も評価が高かった「辛口」なモデルを採用することにしたんです。
ただ、LAPRASのエンジニアにはこれが刺さる、というのは分かりましたが、世の中のエンジニアの皆様が本当にこれを好んでくれるのかは、今後注意深く見ていきたいと思います。
――社内のリアルな声が反映されているんですね。ver.1の評価・レビューと比べて、具体的にどのような違いが生まれたのでしょうか?
田嶋さん:これは私たちの感覚値も大きいのですが、検証を始めた段階で「これは絶対にいける」と確信できるほど、出力されるレビューの中身が以前とは明確に変化した印象を受けました。
2年前のver.1は、ある程度決まった型やパターンに沿った、少し定型的なレビューという印象だったんです。しかし、新しいモデルの場合は、いわゆる生成AIらしい柔軟なアウトプットが可能で、レビューを受け取った人が「自分の記事に対して、自分ごと化されたアドバイスをもらえた」と感じられるような、質の高いものに進化していました。
――レビューの品質に大きな手応えを感じられたのですね。
田嶋さん:はい。実は、当初の計画ではレビューのUI(画面デザイン)の更新までは考えていなかったんです。単純に裏側のモデルを入れ替えるだけの、いわば「静かなアップデート」になる予定でした。
しかし、出てきたアウトプットの質があまりに高かったので、「このレビュー品質の変化を、ユーザーにもっとしっかり認知してもらいたい」と考えが変わりました。
そこで「AIレビューの中身自体が進化している」ということがパッと伝わりやすいよう、これまで表示していなかった各評価項目の詳細なフィードバックまで見せられるようにUIを改修し、大々的にリリースする方針に切り替えた、という経緯があります。自分たちが面白いと感じたものを、世の中にもきちんと届けることで「LAPRASがまた、なにかおもしろいことやってるな」と感じてもらいたいという思いが形になった開発でしたね。
LAPRASの採用知見が集約された「AIスキルハイライト」
――続いて、「AIスキルハイライト」機能についてお聞きします。こちらは採用担当者向けの機能ですね。開発において、どのような点を意識されましたか?
<AIスキルハイライトとは?>
- 候補者の職歴や職務要約といった情報をAIが読み込み、「ピープルマネジメント」「エンジニアリード」「PM/PL」など、特定のソフトスキルに基づく経験を自動で判別し表示する機能です 。
- 職務経歴に明記されていなくても、AIが多様な表現から情報を判別するため、潜在的なスキル保有者を見つけやすくなります。これにより、採用担当者のスクリーニング業務の効率化をサポートします 。
▼詳しくはこちら
田嶋さん:そうですね、身も蓋もない話ですが、この機能はLLMの利用コストが結構かかるので、開発時に「無駄撃ちしないように」というのは常に意識していましたね(笑)。
それよりもこの機能開発で本質的に面白かったのは、その成り立ちです。先の「AIレビュー」とは対照的に、この機能はR&Dチームではなく、運用代行チームの課題感を起点に開発がスタートしています。
――運用代行チームが起点、ですか。
田嶋さん:はい。開発初期は、候補者スカウトなどを担当する運用代行チームから「候補者のポートフォリオを元に、”ピープルマネジメント”などの経験をタグ付けしたい」といった要望を受け、私たちR&Dチームがプロンプトを作成していました。
しかし、ここで最初の壁にぶつかりました。一口に「ピープルマネジメント」と言っても、その定義が運用代行チーム内のメンバー同士の認識でも微妙に異なっているということです。みんな、なんとなく“ふわっと”漠然としたイメージで捉えていたんですね。
なので、最初に私たちが作ったプロンプトから、どのように運用代行チーム全員が良いと思えるものに仕上げていくかが課題でした。
――「言葉の定義」を揃えるのが大変だったのですね。どのように乗り越えたのでしょうか?
田嶋さん:発想を転換して、プロンプト自体を運用代行チームの廣瀬に作ってもらうことにしたんです。課題を最も深く理解している当事者が、直接AIをチューニングする方が早い、と。
さらに、運用代行チームのメンバーがAIの出力結果を評価し、すぐにフィードバックできる仕組みも用意してくれました。そうやって改善のサイクルを回していくうちに、いつの間にかAIスキルハイライトが運用代行チームの「所有物」のようになっていき、彼ら運用代行チームが主体的に改善を進めてくれるようになったんです。
私たちR&Dチームが「研究室に閉じこもるようにして作る」のではなく、運用代行チームとの連携の中で、いつしか自分たちの手を離れて機能が成長していく⋯。このプロセスは、非常に面白く、部門間連携の成功例だと感じています。
――技術的な独自性という点では、そのプロンプトに秘密があるのでしょうか?
田嶋さん:そうですね。そのプロンプトは、廣瀬が運用代行チームのメンバーに何度もヒアリングを重ねて誕生したものです。
たとえば、LAPRASにとっての「ピープルマネジメント」とは何かを考えると、単なるタスク管理や1on1の経験だけでなく、「チームメンバーの人事評価や報酬・昇進の決定に関わった経験」といった、具体的な定義が浮かび上がってきます。
そうして突き詰め言語化された、まさに「LAPRASがこれまでに蓄積してきたエンジニア採用知見の結晶」がこのプロンプトには内包されています 。それ自体が、私たちの大きな資産であり、独自性だと考えています。こうした私たちのならではの知見が、採用担当者の皆様の助けになれば嬉しいですね。
「市場価値スコア」の公平性を支える、スキルの“網羅性”へのこだわり
――次に「市場価値スコア」についてお聞きします。
<市場価値スコアとは?>
- LAPRASに登録された職歴情報などをAIが分析し、ITエンジニア転職市場における現在の競争力、市場価値を数値で示す指標です。
- 技術力だけでなく、ピープルマネジメントやプロダクトへの貢献といった多角的な観点から総合的な価値を評価する。スコアはLAPRASユーザー内での相対評価となっており、自身の市場における立ち位置を客観的に把握できます。
▼詳しくはこちら
https://corp.lapras.com/news/1166/

田嶋さん:はい。私たちR&Dチームが主に関わったのは、スコアを算出する元となる約300のスキル項目を整備し、ユーザーの情報を分類する基盤部分です。算出されたスコアを最終的にどう調整するか、といった部分は別の担当者にバトンタッチしています。
――なるほど、スコアの土台作りをされたのですね。その上で気を付けた点はありますか?
田嶋さん:スキルの「網羅性」ですね。市場価値スコアは2023年にα版として一度リリースしているのですが、当時はスキル項目が100個程度と少なかったため、特定の専門分野の方のスコアが不当に低く算出されてしまうというなどの課題がありました。
ですので、今回は様々な職種のエンジニアの方々を公平に評価できるよう、スキルの網羅性を高めることを特に意識しました。
――スキルの網羅性を高めることで、職種による有利不利が生まれないようにしたんですね。
田嶋さん:はい。また、これは開発の裏話ですが、スキル分類に用いるAIモデルを選定する際に様々なモデルを検証した結果、高価な最新モデルでなくとも、比較的安価なモデルで十分な精度を出せることに気がつきました。これにより、機能の品質を担保しつつ、コストを大幅に抑えることにも成功しています。
森元さん:この領域の開発は、過去のα版や過去の類似する開発経験などを含めるとチームとしては3回目の挑戦になるので、知見が溜まっていたのも大きいかもしれませんね。
田嶋さん:そうですね。ですので、今までの知見を活かしてさらに機能の精度を高める方向で進めた開発でした。
ユーザーの感情を動かす「キャリア市場価値レポート」
――続いて「キャリア市場価値レポート」ですが、こちらはどのような点に注力されましたか?
<キャリア市場価値レポートとは?>
- AIがユーザーの職務経歴情報や、LAPRASが保有する最新の求人データ、企業からのスカウトといった実際の評価情報を深く分析する機能です。
- 分析結果は、市場における強みや立ち位置を示す「総評」や、「テクノロジー」「マネジメント」など4つのキャリア特性の点数と評価コメント、さらには技術領域ごとの詳細な評価などを通して、まるで「通信簿」のように提供されます 。これにより、ユーザーは自身の市場価値という「現在地」を客観的に把握できます 。
▼詳しくはこちら
https://corp.lapras.com/news/1173/

田嶋さん:この機能の開発から、特に意識し始めたのが「狩野モデル」という考え方です。
(編集部注:狩野モデルとは)
顧客満足度に影響を与える品質を
- 当たり前品質(ないと不満だが、あっても満足には繋がらない)
- 一元的品質(あればあるほど満足度が向上する)
- 魅力的品質(なくても不満はないが、あると満足度が大きく向上する)
などの5つに分類するフレームワーク。
狩野モデルを意識し始めたのは、キャリア市場価値レポートを作っていく上で、ユーザーに「面白い」と感じてもらうことが不可欠だと考えたからです。
レポート化のような「AIが作成した文章が人に示唆を与える」という機能は、誰かの日常作業を直接的に効率化するものではありません。だからこそ、単に出力された情報が正しいという「当たり前品質」を追求するだけでは不十分です。
利用者の体験としては、エンターテインメント的な意味合いが強く、レポートを読んだユーザーが「嬉しい」と感じたり、なにか新しい発見があったりといった、感情を動かす「魅力的品質」がなければ意味がない、ということをチームで強く意識するようになりました。
――なるほど。機能の性質上、ユーザーの感情に訴えかける品質が重要になる、と。その上で、開発面でのご苦労はありましたか?
田嶋さん:そこは森元が主担当でしたね。
森元さん:はい。一番の課題は、プロンプトに入れることができる情報量の上限でした。ユーザーの中には非常に多くの職歴をお持ちの方もいらっしゃいます。
そこで、様々なユーザーの職歴データ量を定量的に分析し、「最大で何件の職歴情報をインプットすれば、品質を担保しながら安定して動作させられるか」という最適なラインを見積もる作業に時間をかけました。
――技術的な制約の中で、品質を追求されたのですね。他にこの機能ならではの独自性はありましたか?
森元さん:そうですね。ユーザー一人ひとりに対して「キャッチコピー」を生成する機能は、他にはあまりないユニークな点として、テスト段階から良い反応をいただけました。
――キャッチコピーですか!たしかにあまり他のツールでは聞いたことのない機能ですね。
森元さん:はい、技術的な独自性とは少し違うかもしれませんが、これもまた「面白い」と感じてもらうための、魅力的品質の一部に寄与できていれば嬉しいです。
「おすすめ求人」で定義する「良いマッチング」とは
――本日5つ目の機能となりますが、「おすすめ求人」について聞かせてください。
<おすすめ求人とは?>
- LAPRASに登録されたユーザー情報や活動履歴を基に、一人ひとりにパーソナライズされた求人を一覧で表示する機能です。
- R&Dチームが継続的にアルゴリズムの改善を行っており、ユーザーと企業との最適なマッチングを通じて、最終的な内定受諾数を増やすことを目指しています 。
田嶋さん:はい。「おすすめ求人」は2024年末に正式リリースして以来、私たちR&Dチームがロードマップの策定から改善施策まで一貫して担当しています。
他の機能の場合、他部署からの依頼から始まること多いのですが、このプロジェクトは私たち自身が起点となって進められています。まず「良いマッチングとは何か?」を文章で定義し、そこからゴールを設計していく、という開発の根本の部分から自分たちで手掛けられたことから、チームとして納得感を持ちながら進められました。
――なるほど、具体的にどんな流れで開発を進めていったのか教えてください。
田嶋さん:はい。『A/Bテスト実践ガイド 真のデータドリブンへ至る信用できる実験とは (アスキードワンゴ)』という書籍を参考に、私たちはゴールと3つの指標(メトリクス)を設計しました。
- ゴール(文章):まず、いきなり数値を決めるのではなく、「何を達成したいか」を文章で明確に定義しました。
- ゴールメトリクス:その上で、プロジェクトが最終的に目指す定量的な指標を定めます。私たちの場合「おすすめ求人を経由した内定受諾数」です。
- ドライバーメトリクス:ゴールメトリクスは結果が分かるまで数ヶ月かかってしまいます。そこで、A/Bテストを1ヶ月程度の短いサイクルで回せるよう、先行指標となる「興味ありのクリック数」をドライバーメトリクスとして観測しています。
- ガードレールメトリクス:新しい施策によって既存の体験を損なわないための指標です。例えば「おすすめされる求人が特定の企業に偏りすぎていないか(カタログカバレッジ)」などを設定し、常に監視しています。
――なるほど、非常に体系立てられたアプローチですね。技術的な独自性についてはいかがでしょうか?
田嶋さん:私たちのレコメンドは、一般的に「内容ベース」と「協調フィルタリング」と呼ばれる2つの手法を組み合わせた、ハイブリッドな方式を採用しています。
「内容ベース」は、ユーザーご自身の情報と求人票の情報をもとにおすすめを生成するものです。一方で「協調フィルタリング」は、ECサイトなどでよくある「この商品を買った人はこんな商品も買っています」という表示と同じように、他のユーザーも含めた行動データ(LAPRASでは「興味あり」のアクションなど)をもとにおすすめを生成します。この両方の長所を組み合わせているのが特徴です。
――「おすすめ求人」で、良いマッチングが生まれやすくなるコツなどあるのでしょうか。
田嶋さん:これはLAPRASをご利用いただいている採用担当の皆さんへのお願いなのですが、ぜひ求人票の情報を充実させていただけると嬉しいです。おすすめ求人のレコメンドの精度は、インプットとなる求人票の質に大きく左右されます。
情報が薄い求人票ですと、AIが特徴を捉えきれず、結果的にあまりマッチしないユーザーにおすすめされてしまう可能性も出てきます。求人票を充実させていただくことが、より良いマッチングに繋がります。
R&Dチームの開発理念:仮説検証のサイクルとユーザーの心を動かす品質設計
――これまで5つの機能についてお聞きしてきましたが、最後にチーム全体としての開発理念や価値観について教えてください。
田嶋さん:はい。私たちR&Dチームは、昔からスローガンのようにチーム内で共有している言葉があります。それは「問題領域について素早く継続的に学びと仮説検証を繰り返していくチームでありたい」ということです 。これが私たちの独自性の源泉になっていると考えています。
――その理念を実践する上で、何か具体的なフレームワークや考え方はありますか?これまでの話では「狩野モデル」が出てきていましたが。
田嶋さん:そうですね。「狩野モデル」は、私たちの開発、特にAIが文章を生成するような機能の品質を考える上で、非常に重要な役割を果たしています。
森元さん:この考え方はキャリア市場価値レポートの開発で本格的に言語化しましたが、それ以前の市場価値スコアの初期リリース時にも、すでにこのモデルを用いて検討していました。
――狩野モデルをどのように活用されているのでしょうか?
田嶋さん:このフレームワークが便利なのは、「守るべき品質を、どこで・誰が守るのか」を明確に切り分けられる点です。
例えば、狩野モデルにおける「当たり前品質」は、プログラム側で検証し、保証することができます。具体例をあげると、「日本語で出力すべき箇所が英語で出力されていないか」といったものですね。
一方で、キャリア市場価値レポートなどで重視した「魅力的品質」は、プログラムだけでは保証できません。ユーザーに新しい発見を与えたり、心が動かされたりするような要素は、私たち開発者自身が何百回も評価セットを動かし、定性的・定量的な両面から判断して初めて担保できるものです。
AIレビューやキャリア市場価値レポートといった機能は、ある意味でエンターテイメントだと捉えています。ユーザーの心を動かし、何かしらの価値を感じてもらえなければ、ただの文章でしかありません。私たちは狩野モデルという共通言語を使うことで、こうしたエンドユーザーファーストの視点を常に忘れずに開発や検証を進めることを徹底しています。今後も、守るべき品質の観点を洗い出すためのツールとして、このモデルを積極的に活用していきたいですね。
AIと人材領域の未来:企業側での活用と「人間による責任」の重要性
――昨今、様々な領域でAI活用が進んでいますが、お二人は「人材領域」において、AIは今後どのような役割を担っていくと考えていますか?
田嶋さん:あくまで「人間を補助する」という役割ですが、特に企業側の採用活動においては、かなりの負担軽減に寄与すると考えています。AIの出力を人間が必ず確認し、最終的な責任を持つ、という前提で活用するのであれば、活用の余地は非常に大きいと感じています。
――企業・採用担当者側での活用に大きな可能性がある、と。
田嶋さん:はい。私たちが今、候補者向けに提供しているAIレビューのような機能は、基本的に人間による確認が介在していません。これは企業側での活用とは少し雰囲気が異なります。
人材領域においては、AIの出力を鵜呑みにするのではなく、採用担当者の方が自らの責任でAIを「活用する」という姿勢が何よりも大事になると思います。
――なるほど。一方で、候補者側の体験はどのように変わっていくでしょうか。
田嶋さん:今後は、候補者もAIを使ってキャリアに関する意思決定をするのが当たり前になるでしょう。そうなると、採用側としては、候補者だけでなく、彼らが使うAIにとっても理解しやすい求人票や企業情報を発信していくことが、これまで以上に重要になると考えています。
LAPRASのこれから:候補者と企業の“最適なマッチング”を目指して
――最後に、R&Dチームとしての今後の開発展望についてお聞かせください。
田嶋さん:まだ具体的な時期などはお約束できないのですが、長期的には実装したいと考えている構想がいくつかあります。
現在、候補者の方におすすめ求人を提示しているように、今後は企業様に対して「その企業へのおすすめ候補者」を提示する機能を実装したいと考えています。候補者側と企業側、その両方へのおすすめ機能があって、初めて理想的な「マッチング」が成立すると考えているからです。
将来的には、候補者と求人との「マッチスコア」のようなものを提示するところまで見据えています。もちろん、現在提供している候補者向けの求人おすすめ機能も、継続して改善を続けていきます。
ユーザーと企業の双方にとって、最善の選択肢を提示できるような仕組みを目指して、これからも開発に取り組んでいきます。
ーーありがとうございました!
AIが「作る役割」を担う今、エンジニアの役割は「技術で事業成長を導く」ことへと変わりつつあります。
採用市場では、従来の開発力に加え、「事業貢献」に直結するスキルの重要性が高まっています!
- 課題解決能力:顧客やビジネスへの深い理解で、技術を価値創出につなげる
- 技術応用力:新しい技術(特に生成AI)でチームの生産性を高める
- マネジメント能力:戦略策定・組織運営・人材育成で事業成長を牽引する
こうしたスキルを持つ人材は、従来の経歴書だけでは見極めが困難です。
LAPRASなら、「AI時代に求められるエンジニア」とそのスキルを、独自のアプローチで可視化できます。
▼詳細はこちら▼