
2023年10月3日に、株式会社IVRy、LAPRAS株式会社、Sansan株式会社、Ubie株式会社(発表順)による合同イベント「各社のLLMをプロダクトに組み込む勘所」が開催されました。今回は、各社の事例をもとに、LLMをプロダクトに組み込む際の実践的な知見を共有した、イベントの様子をお届けします。
目次
高いprecisionが要求されるLLMサービスのアルゴリズムデザイン(株式会社IVRy)
登壇者:Principal AI Engineer / べいえりあ ミシガン大学で物理博士、ニューヨーク大学でデータサイエンス修士を取得。 Remo開発チームでのインターンを経験し、 Google Bardを開発したチームのひとつでテックリードを務めた。現在は株式会社IVRyでPrincipal AI Engineerを担当。
べいえりあさん:今回話す中でのPrecisionは、一般的に機械学習で使われる定義とは少し違うため、まずはその点について説明します。
ユーザーが要求したことに対してLLMのサービスが何かを返す際、エラーのパターンは以下の3つだと思っています。
1.何も返答できない
2.正しい情報は返しているが、要求に応えていない
3.間違った情報を与えてしまう
例を挙げると「営業時間を教えて」という要求に対して、1は何も答えない、2は「天気がいいですね」などの正しいけれども関係ない情報を与えてしまう、3は間違った営業時間を教えてしまうというエラーです。
1と2は間違った情報は与えていないのでそこまでのインパクトはないですが、3はユーザーの行動に影響を与えるような間違った情報を与えてしまうため一番クリティカルなエラーです。今回、私がPrecisionエラーと言ったら3を指していると思ってください。
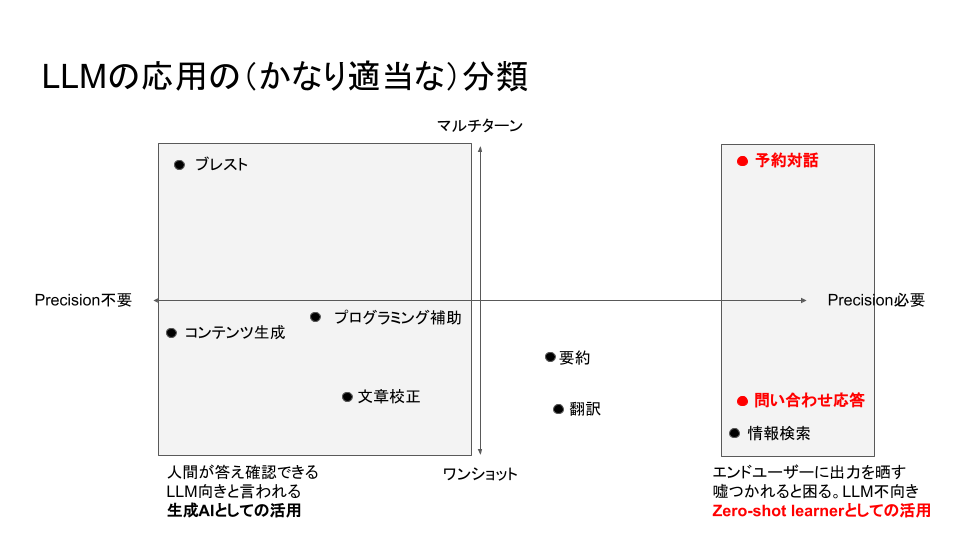
LLMを生成AIではなくZero-shot learnerとして使う
べいえりあさん:LLMサービスを大きく分けると、Precisionが必要なもの・必要ではないものに分類されます。
ブレストやブログなどのコンテンツ生成、プログラミングの補助などは、後で人間がチェックするのが前提になっているので、間違っていても比較的問題になりにくいです。こういったユースケースにおいては、生成AIとしてLLMを使うといいんじゃないかと思います。
一方でサービスの出力が、そのままエンドユーザーに晒されるサービスにはPrecisionが必要です。情報検索が典型的な例で、体調が悪くて症状を検索したり、お店の営業時間を検索したりした場合に間違った情報を与えてしまうケースが考えられるため、こういったユースケースには生成AIとしてのLLMには向いていないと言われがちです。
たしかにLLMを生成AIとして使うとあまり向いていないのですが、Zero-shot learnerとして使うとこれらのユースケースでもLLMは結構使えると思っています。
IVRyではLLMを使って、予約対応と問い合わせ対応をおこなう電話自動応答システムを開発しています。
LLMを用いたend-to-end問い合わせ応答システムの問題点
べいえりあさん:LLMを用いた問い合わせ応答システムを作る場合、まず最初に思いつくのはend-to-endでLLMを使うことかと思います。この場合、LLMの応答は基本的にはプロンプトで制御し、また予約システムの場合は外部のAPIを叩く必要があるため、function callingなども使用します。
プロンプトの例を挙げると「あなたはレストランの店員です。お客様からの予約電話に対応してください」と指示して、予約に必要な情報を与える形が一般的です。弊社も初手としてこの方法を用いましたが、いろいろと問題が発生しました。
みなさんご存知かと思うのですが、LLMは結構適当なことを言います。実際にend-to-endのシステムを実装してみたところ、「明日の11時に予約したい」という問い合わせに対して、空席確認をせずに「満席です」と回答してしまうなどの事態が起こりました。このように勝手に予約を断ってしまったりすると予約システムとして使い物にならないため、本番環境には出せません。
この問題を解決するため、注意事項として「お客様の指定した条件で空席があると仮定して対応してください」という指示を追加するというのもやってみました。ただ、LLMはプロンプトの指示に必ずしも従ってくれるわけではないため、それでもプロンプトを完全に無視して「明日の11時は満席」と対応してしまうケースがかなりの頻度で起きました。
それ以外にも、ユーザーに対しては「予約を完了しました」と返しているにも関わらずfunction callingが呼ばれていなかった(システム上は予約を完了していない)という事象が発生したり、プロンプトインジェクションを防ぐのは難しかったりで、end-to-endのシステムで本番運用に耐えうるprecisionを実現するのは難しいんじゃないか、というのが作ってみての印象でした。
ここで一つ注意しておきたいのが、end-to-endのシステムは本番環境に載せるには厳しいのですが、社内で使ってもらってみての評判は非常に良かったということです。確かに、end-to-endのシステムは会話体験は非常にスムーズなのでクリティカルなprecisionエラーを引かなければ体験は良いと思うのですが、本番環境に出して良いかは体験の良さだけで決めてはいけないということかと思います。
LLMの出力はユーザーに晒さない/LLMに構造化データを出力させる
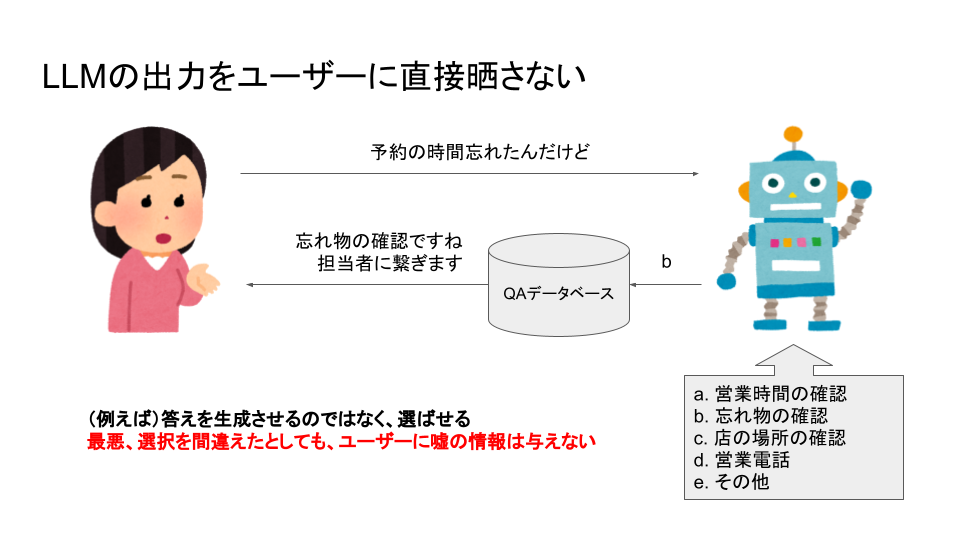
上記のようなprecisionエラーを避けるためにはどうすれば良いかと言うと、「LLMの出力を直接ユーザーに晒さない」に尽きると思っています。
そのため、LLMに自由に対応を生成させるのではなくて、LLMにユーザーの意図を数ある選択肢から選ばせて、意図が分かればそこから対応の生成まではQAデータベースを作ってルールベースで生成させる形にしました。この形であれば、意図を取り違えた場合も、LLMが事実をでっち上げたりせずQAデータベースに登録された数ある事実の中から出力がルールベースで生成されるので、最初に述べたような意味でのprecisionエラーは起きないと考えています。
例えば「予約時間を忘れた」と問い合わせた際、与えられた意図のリストの中には該当するものが存在しないので、ChatGPTは「その他」をユーザーの意図として選ぶべきですが、それを間違えて「忘れ物の確認」を選んでしまうケースがあります。この場合でも結果としてユーザーへの対応は「忘れ物のご確認ですね。担当者に繋ぎます」となるので、間違った予約時間を与えるような最悪の事態は避けることができます。
LLMを使ってテキスト生成をしないなら使う意味がないと思われるかもしれませんが、ユーザーが求めるのは、なめらかな会話ではなく確実な予約や正確な情報です。多くのユースケースにおいて、テキスト生成はユーザーが求めるものではないと個人的には考えています。
ユーザーは何を求めていて、何をLLMで何を解決するべきなのかを考えることが重要です。
解決するためのサービスを開発するなかで一番難しい部分を、機械学習モデルからZero-shotやFew-shot learnerとしてのLLMに置き換えます。
LLMで生成した構造化データを利用する際の利点として、出力の制御やバリデーションがしやすく、JSONに落とせば精度評価もしやすくなる点が挙げられます。
ChatCPTは出力が長くなるとレイテンシが大きくなるので回答が永遠に返ってこないケースがあると思いますが、JSONは基本的に固定長で出てくるので本番環境向きです。
Q&A
Q.社内では評判がいいサービスが、本番環境では難しいと判断されたのは何故ですか?
A.評判が良かったのは、体験が良かったところだけ。会話のフローがスムーズだったとか。
製品としてみるとやばいprecisionエラーがそれなりの確率で発生するとなると使い物にならない。みているところが違ったのかなと。
ユーザーはやばいハルシネーションが起きたところをみなければ、すごい体験がいいので。でもみてしまうとやば
Q.QAデータベースの作成は、人力ではなくLLMの力を使って効率化したのでしょうか。
A.企業秘密なので具体的には言えませんが、初手は人力がいいと思っています。その後、もっとスケールさせたいと考えた場合はLLMを使うといいのではないでしょうか。
AIプロダクトがLLMで変わったこと/変わらないこと(LAPRAS株式会社)
登壇者:プロダクトマネージャー/ R&D責任者 /鈴木 亮太 NEC中央研究所にて機械学習、信号処理の研修を経験。LAPRAS入社後は機械学習エンジニア、リサーチャーを経て現職。
鈴木:LAPRASでは、エンジニアの方が公式にアウトプットしている情報をクローリングすることで、ポートフォリオを作成したりスコアリングをしたりするサービスを提供しています。
それによってエンジニアは市場価値を確認し、エンジニアを採用したい企業は情報を閲覧してオファーを送信し、マッチングします。
質の高いマッチングを実現するために、これまでもAI技術を活用したプロダクト開発をおこなってきました。最近ではLLMを活用した機能をリリースしており、PR上のインパクトよりも「本当に役に立つ機能」を目指して開発に取り組んでいます。

LLMで変わったこと
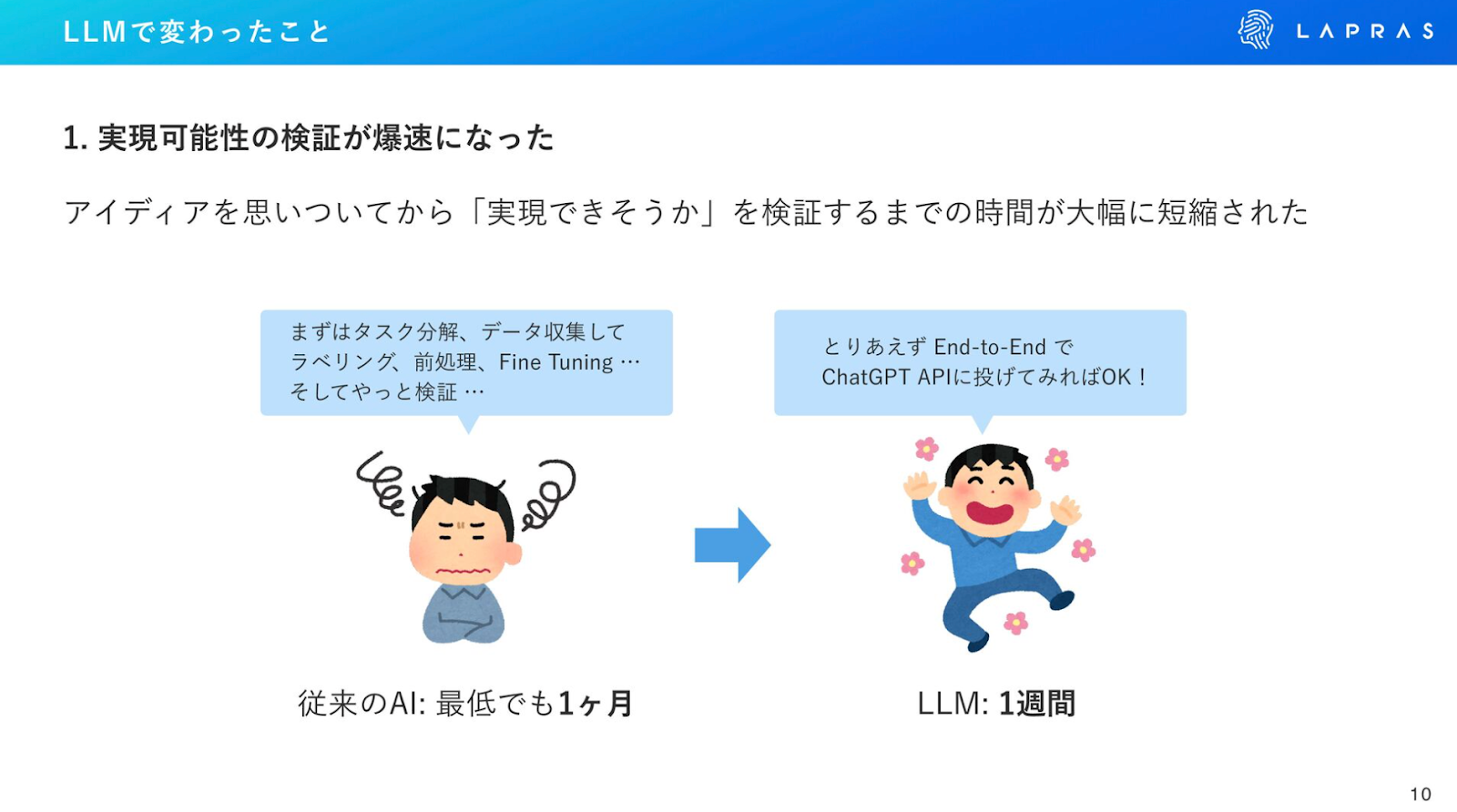
①実現可能性の検証が爆速になった
鈴木:従来のAI開発における検証では、データを収集してラベリングして、複雑なタスクの場合は分解するなどの前処理やファインチューニングをして、やっと実施できます。それだけ時間をかけたにも関わらず、うまくいかないケースも多々あります。
LLMの場合、とりあえずend to endでChatGPTに投げてみれば確かめられるので、1週間ほどで実現可能かどうかを判断できるようになりました。
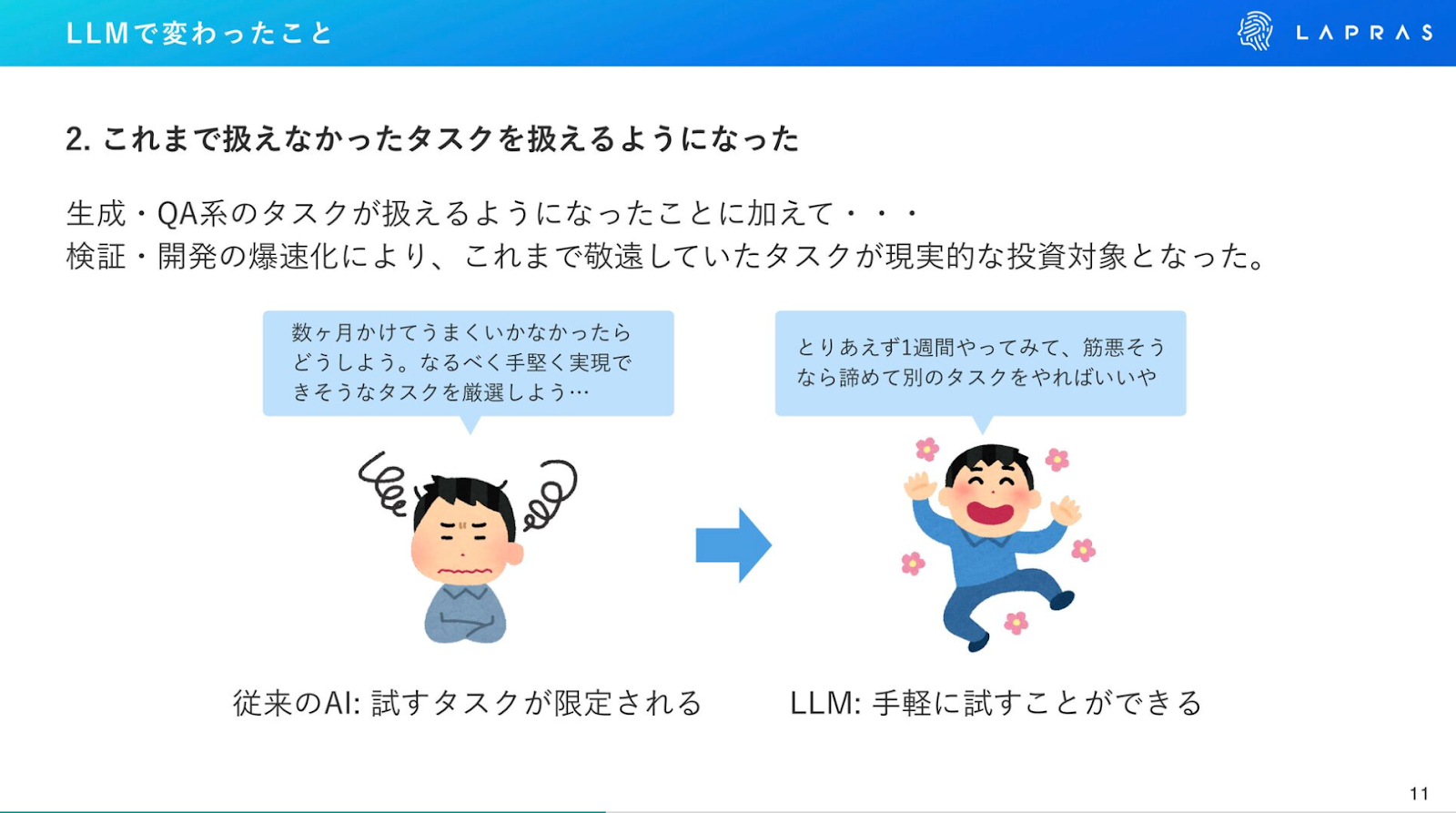
②これまで扱えなかったタスクを扱えるようになった
鈴木:数ヶ月かけて検証・開発をして、結果的にうまくいかなかった場合のリスクを考えて、これまでは手堅いタスクを厳選して取り組んできました。
LLMによって検証と開発が爆速になったので「1週間だけやってみて、ダメなら諦める」という戦略が取れるようになり、敬遠していたタスクを現実的な選択肢に入れられるようになりました。
③常識が変わった
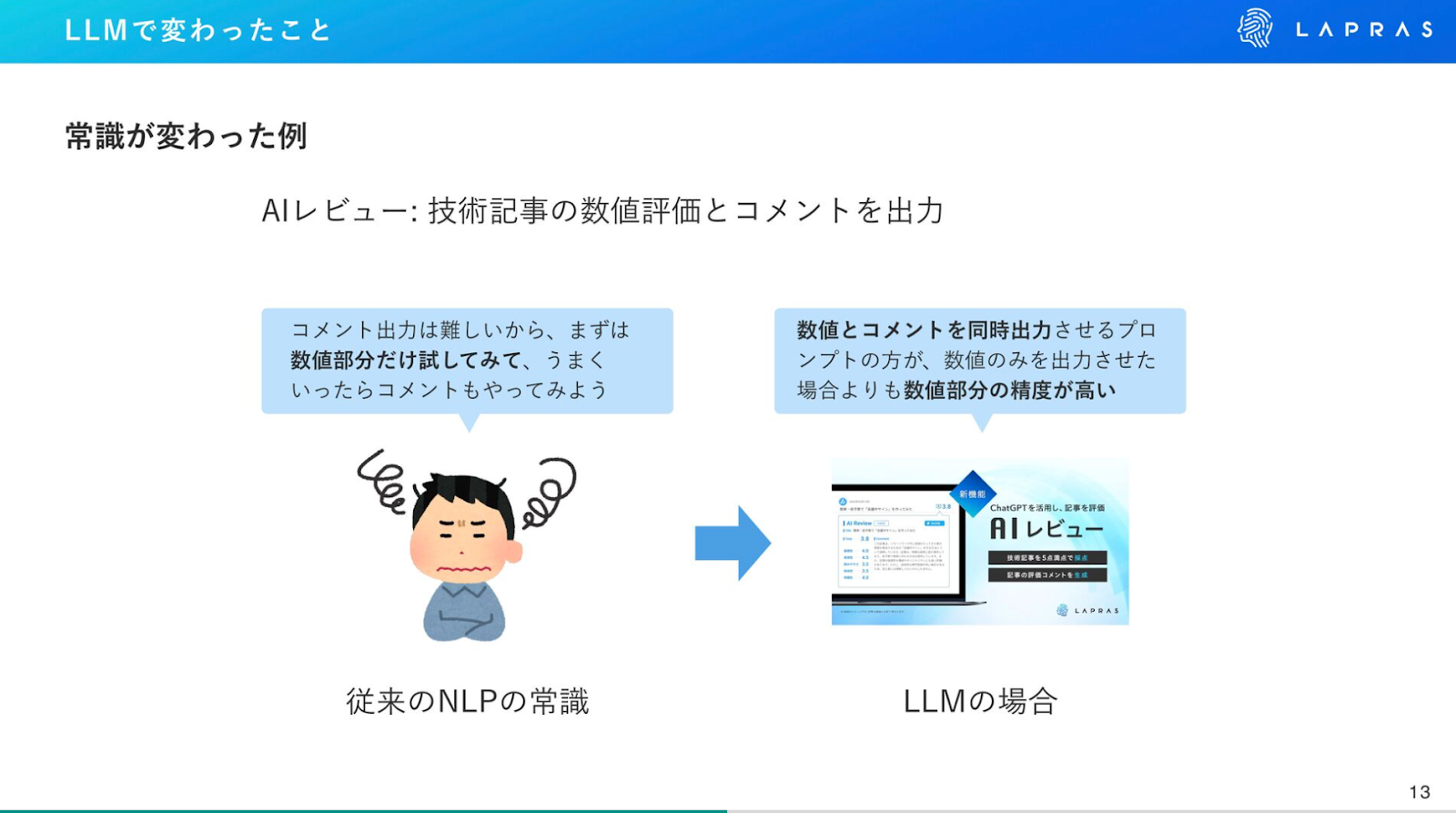
鈴木:これまで述べたように、LLMによってAIの常識は大きく変わりました。これまでの常識が通用しなかった事例として、技術記事に対して数値評価とコメントを出力するLAPRASの「AIレビュー」機能の開発における話を紹介したいと思います。
「AIレビュー」において、コメントの生成・出力は難しいので、まずは数値を出す機能を開発して、うまくいけばコメント機能を追加していくのが、従来の常識でした。しかし、LLMの場合は数値だけを出力させるよりも、コメントも同時に出力したほうが、数値部分の精度が上がります。
コメントで数字の根拠を説明する必要があるため、適当な数字を出さないようになるのです。
LLMでも変わらないこと
鈴木:LLMでAIの常識は大きく変わりましたが、ユーザーの方を向いてプロダクト開発する姿勢は変わりません。
AIを活用してサービスを提供する事業社として、今後もユーザーの価値にコミットし続けていきます。

鈴木:サービスをつくっても、使われなければ意味がありません。「ユーザーが何をできるか」ではなく「ユーザーにどんな価値を提供できるか」を重視し、技術的な検証だけでなく、価値の検証を続けていきます。
ユーザーにAIの面倒を見させないためのAI出力の品質管理も、今後も変わらないサービス提供者としての責務です。
下記の記事は弊社のAIチームが書いたもので、LLMアプリケーションの品質保証のためにおこなっているガードレールテストについて記載されているので、よろしければご一読ください。
LLM活用で大事なこと
①社内での啓蒙
鈴木:ハッカソンや勉強会による、社内での啓蒙活動は重要です。誰でもLLMを使えるようになれば社内のLLMインフラの整備が進み、業務改善にも繋がります。また、さまざまな社員がLLMを使うことで、AIチームにはなかった新たな発想が生まれ、プロダクト実装に至るケースもあります。
実際に「AIレビュー」は、社内ハッカソンから生まれたプロダクトです。前述した、コメントと数字を同時に出力する発想は、従来のNLPの常識の中にいたAIチームにはないものでした。
②法的要件のクリア
鈴木:外部APIに機密情報やユーザー情報を送信するには、法的な要件をクリアする必要があります。LAPRASではユーザー向けにAI利用規約を制定し、個人データに対するLLM利用について包括的な同意を取得する条目を設けており、アクティブユーザーの9割が同意済みです。
③自社ならではの強みの構築
鈴木:LLMはAIを使ったプロダクトの参入障壁を大きく下げます。そのため、「LLMを使うこと」自体は、自社ならではの強みにはなりません。
LLMは自社のアセットを高めるためにこそ使うべきです。弊社の場合は、クロール技術などで集めた独自のデータベースの価値向上、それをどうマッチングに活かしていくかというところに強みを持っていきたいと考えています。
Q&A
Q.ユーザー視点の考え方の汲み取りは、どのような属性の方が担当していますか?
A.AIとプロダクト両方を見ている人間が担当しています。ユーザーへのアンケートやテストをおこなったり、AIチームが直接ユーザーインタビューをしたりと、ユーザー視点での開発のために、さまざまな取り組みをしています。
Q.エンジニア以外への社内啓蒙はどのようにおこなっていますか?また、LLMはどのように社内で活用されていますか
A.開発に活かせるアイデアを出してもらうレベルにまで啓蒙するには、ハッカソンや勉強会で理解を深めてもらう必要がありますが、とりあえずLLMを試してもらうところまでならハードルは低く、すぐに実践できると思います。
社内では、Slackのチャットボットなど、日々の業務の中でLLMが活用されています。
Sansan LabsにおけるGPT活用事例(Sansan株式会社)
登壇者: 技術本部 研究開発部 SocSci Group マネジャー / 西田 貴紀 Sansan株式会社の研究開発部所属。マネージャー兼研究員として、社内外のデータ活用プロジェクトを推進する傍ら、Sansan事業部プロダクト室を兼務し、プロダクトマネジメントに挑戦中。
西田さん:Sansanは「出会いからイノベーションを生み出す」をミッションに、人や企業との出会いをビジネスチャンスに繋げる「働き方を変えるDXサービス」を提供している会社です。
営業DXサービス「Sansan」の中にある実験的な機能群であるSansan Labsでは、データ活用の実験的な機能を多数リリースしています。今回はLLMを使った新機能についてお話しします。
LLM活用で商談準備を効率化
・5分で読める有価証券報告書
西田さん:営業の方が商談準備のために、有価証券報告書を1時間かけて読み込むケースがあり、その業務を効率化するために開発された機能です。有価証券報告書の内容を企業動向や経営課題を5つのトピックに分けて要約した文章が生成されます。元の文章も提示するので、ハルシエーションが生じた際もリスク回避できるようになっています。
画像はSansan株式会社の有価証券報告書を要約したものです。

西田さん:この「5分で読める有価証券報告書」のデータを用いて、さらにLLMを活用した機能をリリースしています。業界の課題や市場環境を抽出・要約した「5分で読める業界動向」、そして経営方針や経営課題から企業を検索し営業リストを作成できる機能である「AI企業検索 -経営方針・経営課題-」です。

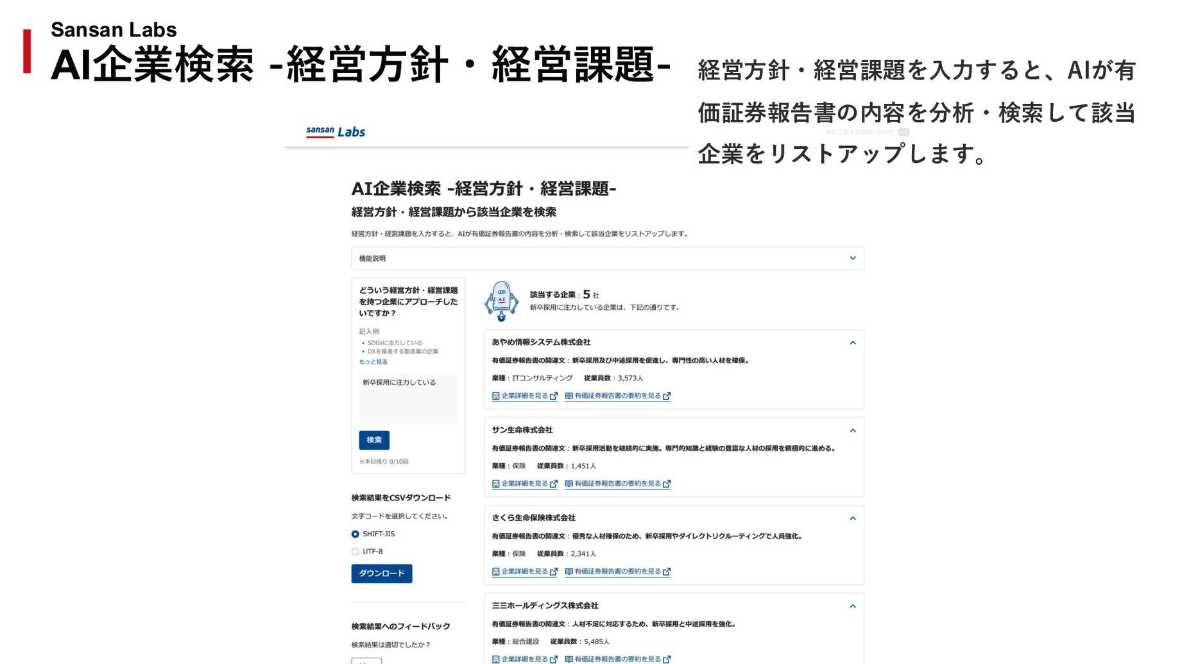
営業活動の様々なシーンに応じて価値提供できる拡張性を意識
西田さん:有価証券報告書のデータに着目して機能開発した理由は、LLMと相性の良い条件に合致し、営業活動で幅広く使われるデータだからです。
LLMは有価証券報告書のような非構造化データを扱い、情報抽出が必要なタスクで活用しやすいです。さらに有価証券報告書は、営業担当者の業務効率化から営業マネジャーやマーケターが業界を理解したうえでの営業戦略の立案する際にも活用できます。様々な活用ができる見通しが立っていたので、段階的に小さくスピード感を持ってリリースできると考えました。
また、オープンデータなのでセキュリティや本部の判断などの論点も少なく、扱っているデータも約4000社とそこまで大きくないので、リリースまでのリードタイムも短くできます。
「5分で読める有価証券報告書」を元に開発したのが、業界動向を把握する「5分で読める業界動向」です。
「5分で読める有価証券報告書」の要約済み有価証券報告書のデータを用いたので、業界ごとに有価証券報告書の原文を全てインプットせずに済むので、コストを抑えることができました。
その後、リリースした「AI企業検索 -経営方針・経営課題-」においても、要約済み有価証券報告書のデータを用いたことで、RAGにおけるレスポンス時間の短縮に繋がっています。
LLMも一般的な機械学習も、プロジェクトの進め方は同じ
西田さん:データ分析のフレームワークであるCRISP-DMに沿って考えると、一般的なデータ分析、機械学習のプロジェクトと、LLMの活用の進め方は変わらないと思っています。ビジネスとデータを理解して、データ準備をモデリングして、ビジネスインパクトに対する評価をして、うまくいかなければビジネス理解に戻るという形で進めます。
LLMの活用においては、特に評価が非常に重要だと感じています。評価の基準が不明瞭だといつまでもリリースの判断ができず、スピード感を持ってリリースできません。評価データセットの作成とその評価基準を決めることを厭わず、やりきることが肝心です。

Q&A
Q.GPT3.5と4は、それぞれどのように使い分けていますか?
A.「5分で読める有価証券報告書」では、まず1回ラフに要約して、さらに要約するというステップを踏んで生成しています。その際の、1回目の要約にGPT3.5を使用することでコストを抑えています。
BigQuery・LLM を活用したユーザーの検索意図分析の事例(Ubie株式会社 Ubie)
登壇者: Lab Head of AI Research / 風間 正弘 リクルートとIndeedで推薦システムの開発に携わり、2020年にUbie入社。社内のAIチームの立ち上げ・推進を担当している。東京都立大学非常勤講師。『推薦システム実践入門(オライリー)』共著者。
風間さん:Ubieは医療×AIのスタートアップ企業で、今はふたつのサービスを主に提供しています。

風間さん:弊社における生成AIによるサービス開発の軸は、プロダクトへの活用と、社内の生産性向上の2点です。
ヘルスケア業界において生成AIの活用はまだまだ未知数なので、業界団体としてガイドラインを制作する取り組みもおこなっています。
社内におけるLLM活用事例
風間さん:機密情報を入力できたり、社内ナレッジをためられたり、URLも共有できる社内用のChatGPTツールをつくりました。従量課金制なので月に数万円程度のコストです。実際の業務で使用することで社員が生成AIに対する理解度を上げて、プロダクト活用に繋げるきっかけにする目的もあります。
アドバンスドアナリティクス、プラグインなども便利で、データのプライバシーやセキュリティの観点を確認した上で、特定のタスクのみに活用しています。。
例えばプラグインで店舗情報を表示して、CSV形式で抽出するとなると地味に大変です。URLを渡せばサクッととCSVで出してくれるので、ときどき間違えているところもありますが、すごく楽ですね。
コードインタープリターもCSVをアップロードするだけでPythonのコード付きで出してくれるので便利です。とりあえず初手はそこに投げてもいいと思います。
ユーザーの検索意図分析の事例
風間さん:症状検索エンジン「ユビー」では、各ページで入力されたキーワードを発掘し、ユーザーの目的を分析して強化すべきキーワードを抽出しています。
まず取り組んだのは、どういう検索クエリでユビーに流入したのかを、Search ConsoleのデータをBigQueryにエクスポートすることです。その後、LLMを活用してSQLを書くだけで、下記のようにユーザーの検索クエリを11種類の目的に分類できます。
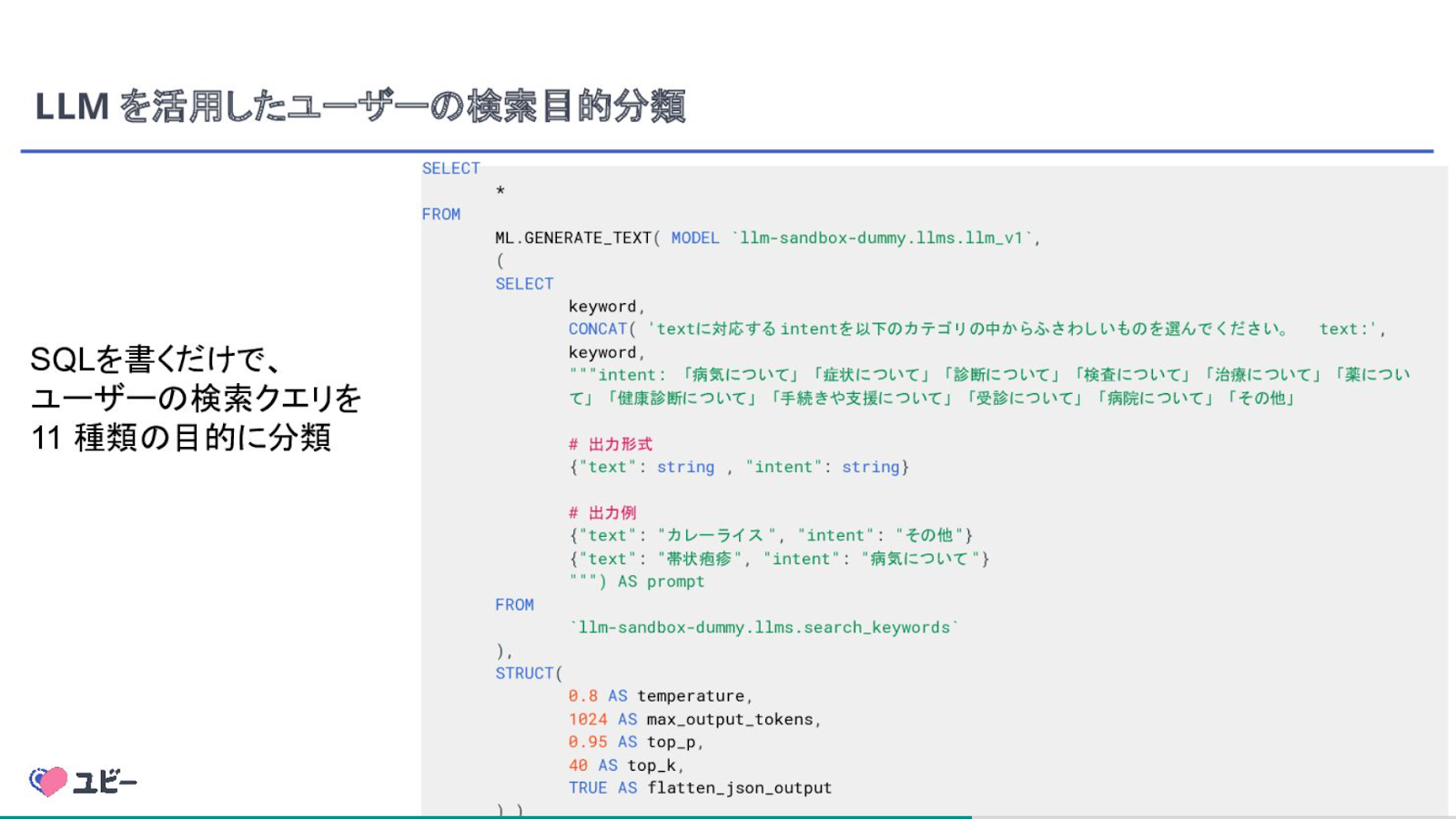
風間さん:生成AIはオープンAI一強ではなくて、それぞれの生成AIに強みがあると、この取り組みで感じました。今後も適材適所で活用していければと思っています。
プロンプトはChatGPT的なもので「テキストに対応するインテントを、以下のカテゴリの中からふさわしいものを選んでください」とします。
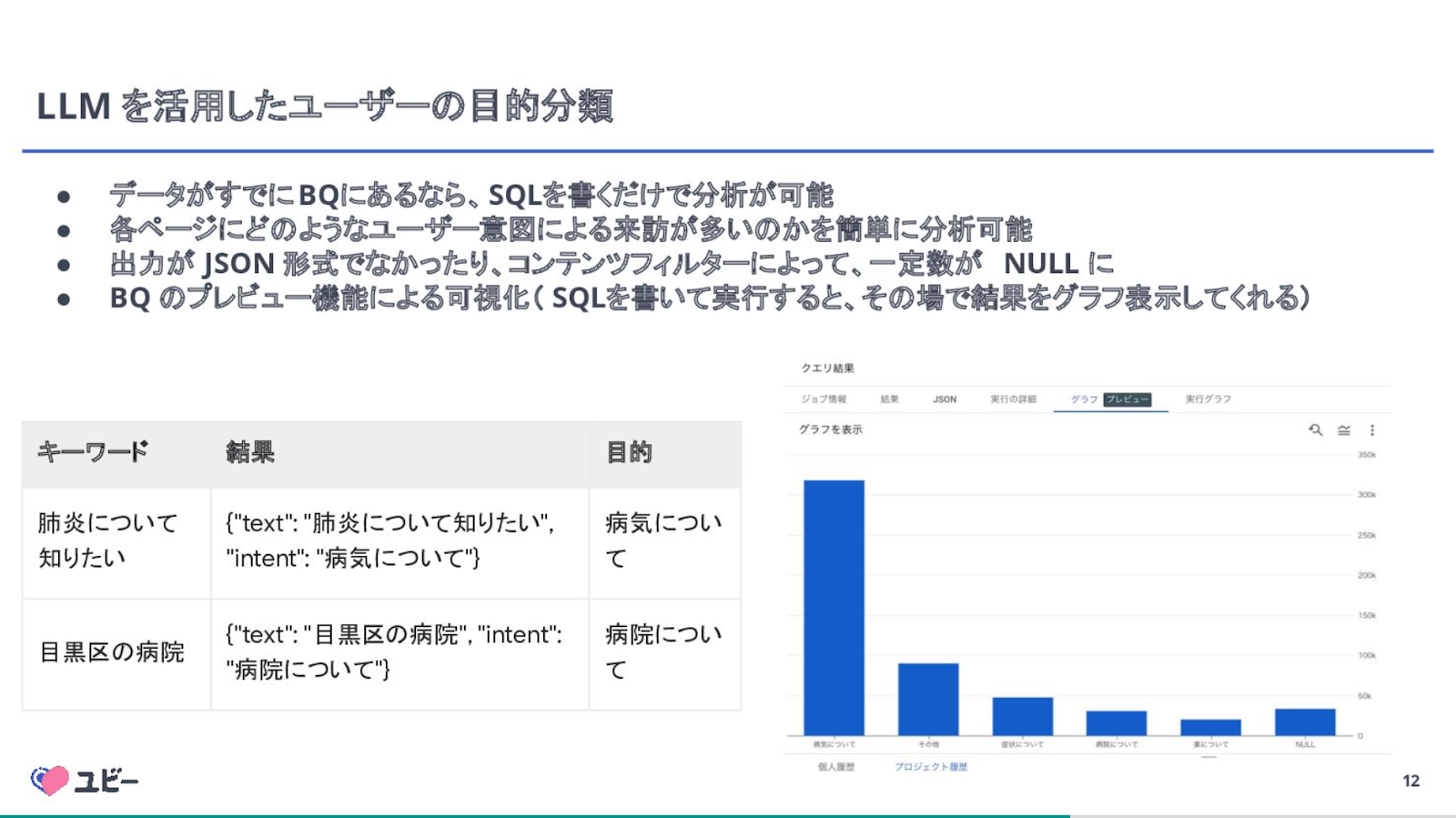
風間さん:画像左のテーブルはユーザーの流入クエリで、そこからキーワードを抽出しています。このキーワードに対して、ユーザーは病気について知りたいのか、症状について知りたいのかを分類します。出力はテキストやインテント形式です。
サンプルとしてFew-shotで「カレーライス」という検索クエリなら「その他」、「帯状疱疹」なら「病気について」と入れて分類すると、ここでパラメーターも指定できます。
キーワード「肺炎について知りたい」からは、「病気について知りたい」という結果と目的が表示されます。BigQueryのプレビュー機能、グラフ機能を利用すれば、各ページに流入したユーザーの目的の中で、一番多かったものも一目でわかります。
ただし、出力がJSON形式ではない事例や、コンテンツフィルターによって一定数がnullになる事例があり、改善が必要だと感じるケースもありました。
効率化に向けたBQとLLMの活用
風間さん:従来の機械学習では、データを収集して、モデル学習して、予測して、システムに組み込むところまで、結構時間がかかります。
そこでまずはBigQueryのスケジュールクエリを活用して、処理のスケジュール化をおこないました。

風間さん:ユーザーの検索意図分析では、ユーザーの検索クエリを11種類の目的に分類した事例を紹介しましたが、これも一からやろうとすると学習データも数万レベルで必要になるため、数ヶ月はかかります。
こちらもLLMのAPIを活用すると学習データはほとんどいらないので、プロンプトエンジニアリングをするだけで済みます。予測はPythonで少し書くだけです。
BigQueryを使えば、予測のシステム化も改善できたかなと思っています。
Q&A
Q.BigQueryの場合、使うLLMはPaLMになると思うのですが、ChatGPT3.5や4と比較した際の精度についての所感を教えてください。ビジネス的には問題ないレベルでしょうか?
A.所感としてはChatGPT3.5くらいです。JSON形式での出力もできて、一定レベルは超えている印象です。分類精度を見てもある程度はそれっぽくできていましたが、4に比べると、やはり少し劣るかもしれません。
ユーザーの目的分類に関しては、大雑把な傾向をケース別に知るためのもので、99%の精度は求めていなかったので問題ありませんでした。
まとめ
各社のさまざまなLLM活用事例をもとに、開発方針やサービスの特性などによって変わる「LLMをプロダクトに組み込む勘所」が共有されました。
このイベントが、LLMの可能性を最大限に引き出し、貴社のサービスに活用するための参考になれば幸いです。
(ライター:成澤綾子)


